Forking
Forking is a mechanism by which workloads can be deployed into a Kubernetes cluster in a Sandbox. At a high level, it takes a baseline workload, applies some customizations to it, and creates a new workload called the forked workload that is tied to the Sandbox.
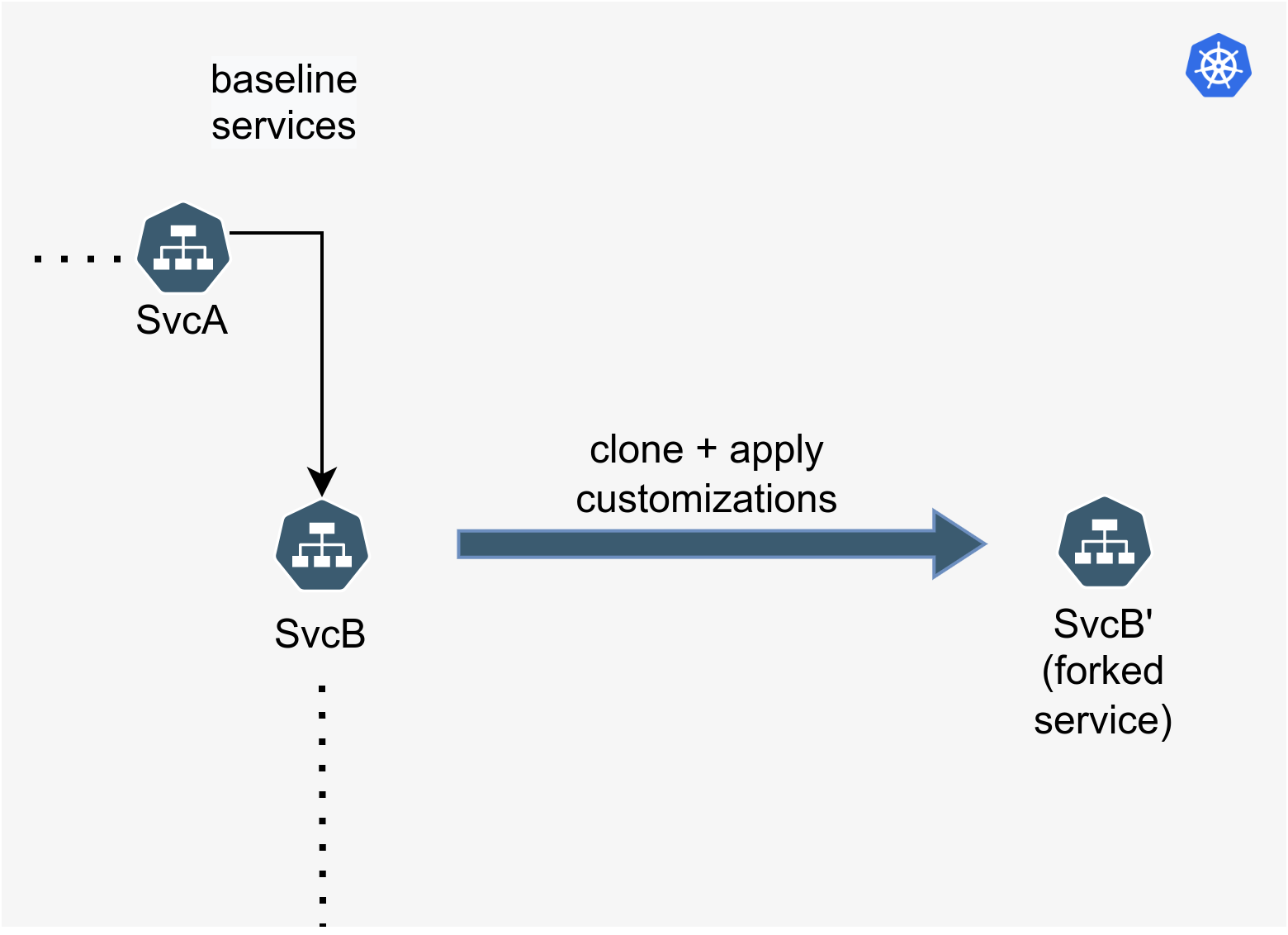
Forking relies on the idea that when it comes to testing a microservice, only a small portion of its specification changes against the baseline environment. Concretely, if all we were testing was a new docker image for a microservice, the specification of a fork looks as below:
forks:
- forkOf:
kind: Deployment
namespace: ...
name: ...
customizations:
images:
- image: ...
...
The baseline workload (Deployment in this case) that we want to derive from is
specified under forkOf, identified by its namespace and name. When a sandbox
containing the above fork specification is created, it will automatically use
that baseline workload's runtime specification in Kubernetes, apply the
specified customizations, and then derive a new forked version of that
Deployment that is specific to the Sandbox. Note that the baseline environment
is never modified as part of this process.